![]()
A lightweight diffusion library for training and sampling from diffusion models. It is built for easy experimentation when training new models and developing new samplers, supporting minimal toy models to state-of-the-art pretrained models. The core of this library for diffusion training and sampling is implemented in less than 100 lines of very readable pytorch code. To install from pypi:
pip install smalldiffusion
To train and sample from the Swissroll toy dataset in 10 lines of code (see
examples/toyexample.ipynb for a detailed
guide):
from torch.utils.data import DataLoader
from smalldiffusion import Swissroll, TimeInputMLP, ScheduleLogLinear, training_loop, samples
dataset = Swissroll(np.pi/2, 5*np.pi, 100)
loader = DataLoader(dataset, batch_size=2048)
model = TimeInputMLP(hidden_dims=(16,128,128,128,128,16))
schedule = ScheduleLogLinear(N=200, sigma_min=0.005, sigma_max=10)
trainer = training_loop(loader, model, schedule, epochs=15000)
losses = [ns.loss.item() for ns in trainer]
*xt, x0 = samples(model, schedule.sample_sigmas(20), gam=2)Results on various toy datasets:

We can also train conditional diffusion models and sample from them using classifier-free guidance. In examples/cond_tree_model.ipynb, samples from each class in the 2D tree dataset are represented with a different color.

We provide a concise implementation of the diffusion transformer introduced in
[Peebles and Xie 2022]. To train a model on the FashionMNIST dataset and
generate a batch of samples (after first running accelerate config):
accelerate launch examples/fashion_mnist_dit.py
With the provided default parameters and training on a single GPU for around 2 hours, the model can achieve a FID score of around 5-6, producing the following generated outputs:

The same code can be used to train U-Net-based models.
accelerate launch examples/fashion_mnist_unet.py
We also provide example code to train a U-Net on the CIFAR-10 dataset, with an unconditional generation FID of around 3-4:
accelerate launch examples/cifar_unet.py

smalldiffusion's sampler works with any pretrained diffusion model, and supports DDPM, DDIM as well as accelerated sampling algorithms. In examples/diffusers_wrapper.py, we provide a simple wrapper for any pretrained huggingface diffusers latent diffusion model, enabling sampling from pretrained models with only a few lines of code:
from diffusers_wrapper import ModelLatentDiffusion
from smalldiffusion import ScheduleLDM, samples
schedule = ScheduleLDM(1000)
model = ModelLatentDiffusion('stabilityai/stable-diffusion-2-1-base')
model.set_text_condition('An astronaut riding a horse')
*xts, x0 = samples(model, schedule.sample_sigmas(50))
decoded = model.decode_latents(x0)It is easy to experiment with different sampler parameters and sampling
schedules, as demonstrated in examples/stablediffusion.py. A
few examples on tweaking the parameter gam:

The core of smalldiffusion depends on the interaction between data, model
and schedule objects. Here we give a specification of these objects. For a
detailed introduction to diffusion models and the notation used in the code, see
the accompanying tutorial.
For training diffusion models, smalldiffusion supports pytorch Datasets and
DataLoaders.
The training code expects the iterates from a DataLoader object to be batches
of data, without labels. To remove labels from existing datasets, extract the
data with the provided MappedDataset wrapper before constructing a
DataLoader.
Three 2D toy datasets, Swissroll,
DatasaurusDozen,
and TreeDatasetare provided.
All model objects should be a subclass of torch.nn.Module. Models should have:
- A parameter
input_dims, a tuple containing the dimensions of the input to the model (not including batch-size). - A method
rand_input(batchsize)which takes in a batch-size and returns an i.i.d. standard normal random input with shape[batchsize, *input_dims]. This method can be inherited from the providedModelMixinclass when theinput_dimsparameter is set.
Models are called with arguments:
xis a batch of data of batch-sizeBand shape[B, *model.input_dims].sigmais either a singleton or a batch.- If
sigma.shape == [], the same value will be used for eachx. - Otherwise
sigma.shape == [B, 1, ..., 1], andx[i]will be paired withsigma[i].
- If
- Optionally,
condof shape[B, ...], if the model is conditional.
Models should return a predicted noise value with the same shape as x.
A Schedule object determines the rate at which the noise level sigma
increases during the diffusion process. It is constructed by simply passing in a
tensor of increasing sigma values. Schedule objects have the methods
sample_sigmas(steps)which subsamples the schedule for sampling.sample_batch(batchsize)which generates batch ofsigmavalues selected uniformly at random, for use in training.
The following schedules are provided:
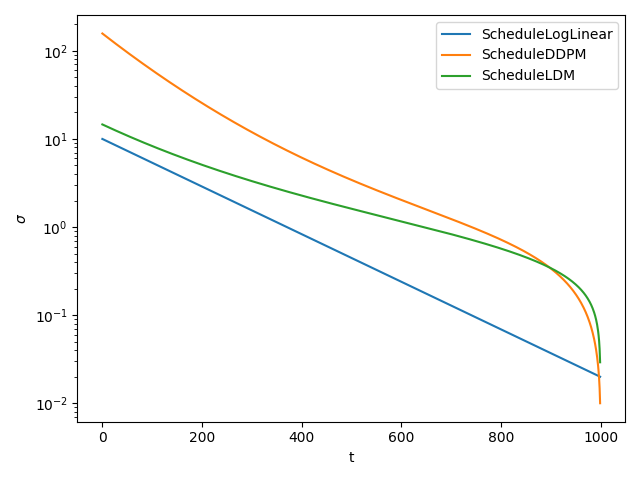
ScheduleLogLinearis a simple schedule which works well on small datasets and toy models.ScheduleDDPMis commonly used in pixel-space image diffusion models.ScheduleLDMis commonly used in latent diffusion models, e.g. StableDiffusion.ScheduleSigmoidintroduced in GeoDiff for molecular conformal generationScheduleCosineintroduced in iDDPM
The following plot shows these three schedules with default parameters.
The training_loop generator function provides a simple training loop for
training a diffusion model , given loader, model and schedule objects
described above. It yields a namespace with the local variables, for easy
evaluation during training. For example, to print out the loss every iteration:
for ns in training_loop(loader, model, schedule):
print(ns.loss.item())
Multi-GPU training and sampling is also supported via
accelerate.
To sample from a diffusion model, the samples generator function takes in a
model and a decreasing list of sigmas to use during sampling. This list is
usually created by calling the sample_sigmas(steps) method of a Schedule
object. The generator will yield a sequence of xts produced during
sampling. The sampling loop generalizes most commonly-used samplers:
- For DDPM [Ho et. al. ], use
gam=1, mu=0.5. - For DDIM [Song et. al. ], use
gam=1, mu=0. - For accelerated sampling [Permenter and Yuan], use
gam=2.
For more details on how these sampling algorithms can be simplified, generalized and implemented in only 5 lines of code, see Appendix A of [Permenter and Yuan].